
Intro
In the age of emerging AI, it is common to focus mental capacity and resources on growth of more and more new algorithms. Interesting and not obvious subjects related to AI still remains relatively untouched. Yet, the pioneer like OpenAI already take a step in the synthetic data and simulation of virtual environments. The synthetic data is understood as generating such data that when used provides production quality models.
In the AI language we are talking about synthetic-to-real adaptation. Therefore, we learn the model on synthetic data with synthetic target to transfer the results to real data and real target. Synthetic data is often correlated with data augmentation, which use is so pervasive in computer vision that it is used in almost all pipelines. Shading, rotation, noising, transforming the images in general can be perceived as creating synthetic data. However there are limits to what you can do using simple data augmentation. For example rotating a 3-dimensional object is not possible.
But we are not comparing image augmentation to synthetic data because we need to take a step back in the process. The real comparison we should be making is: manual annotation vs synthetic data.
| Method | Manual annotation | Synthetic data |
|---|---|---|
| Ease of use | Good There are excellent tools which speed up the process of annotation for deep learning. |
Bad There are no frameworks at the moment of writing. |
| Annotation time | Bad Even if you use image augmentation you still need hundreds to thousands of properly annotated images |
Good The assumption is that synthetic data gives you annotation for free. However you must still wait for the 3D renders to be created. But it is mostly CPU time not human time. |
| Robustness | Limited Depending on the case: rotations, skewing, adding noise, cropping can be not enough to generate robust data |
Very good The assumption is that synthetic data gives you annotation for free and you can create as many scenarios as you want. |
Why the synthetic data generation is important?
The success of AI algorithms relies heavily on the quality and volume of the data. There were made a lot of efforts recently to raise availability, volume and quality of the data. We are in a comfortable position where Deep Learning algorithms can learn almost anything but they need a lot of good quality data. However, generating sufficent data volume is extremely expensive, hence only hi-tech giants can afford it, which stimulates the growth of AI only in a certain limited way. Open source philosophy and access to reliable synthetic data generator can substantialy boost development in such areas like Computer Vision and Reinforement Learning. With data generated like this you can come up with an idea, create artificial data in matter of hours instead of waiting days for human labels.
Blender
If you are doing computer vision we encourage you to take a look at Blender which is an open source software for creating 3D environments. It is really a game changer because Blender (especially since version 2.80) competes with commercial software worth thousands of dollars and some say it is winning the battle. It runs on all platforms Linux, Windows, Mac. It is really a big deal.
Another important feature of Blender is that it is possible to write scripts and addons in Python.
Update 2020-06-03: A colleague presented me with a project BlenderProc that automates generating artificial data using Blender.
Below there is a presentation of this software
Not convinced? Let’s look at a few examples of how you can use this software to create data for your Deep Learning models.
Example 1. Using Blender to create a dataset for classification
Imagine you have an app and you want people to make selfie to authorize. You want to prevent them from using another person photograph. Generating fake photographs could be a lot of work but generating photorealistic artificial ones can be very easy
The first thing is setting up a scene in Blender

Then, create a script to randomize the scene:
- Add random lightning effects: intensity of the light and the position
- Camera position
- Focal length
- Position of the camera
- Rotation of the photo
- Curvature of the photo
- Properties of the photo (noise)
- Reflectiveness of the surface
Blender is using Python as the scripting language so it is possible to change virtually anything in the scene.
The result is randomly generated images that can be used in a deep learning model

Example 2. Using Blender to create dataset for segmentation and depth estimation
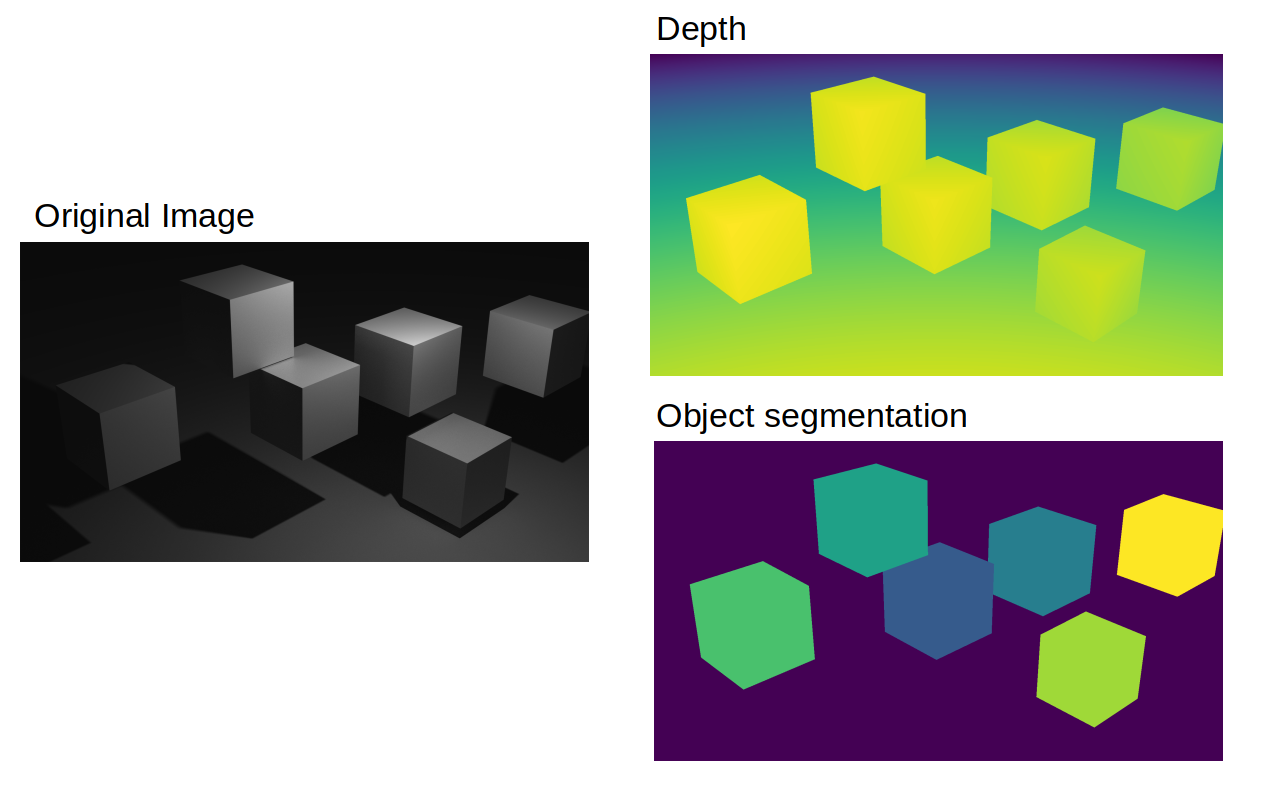
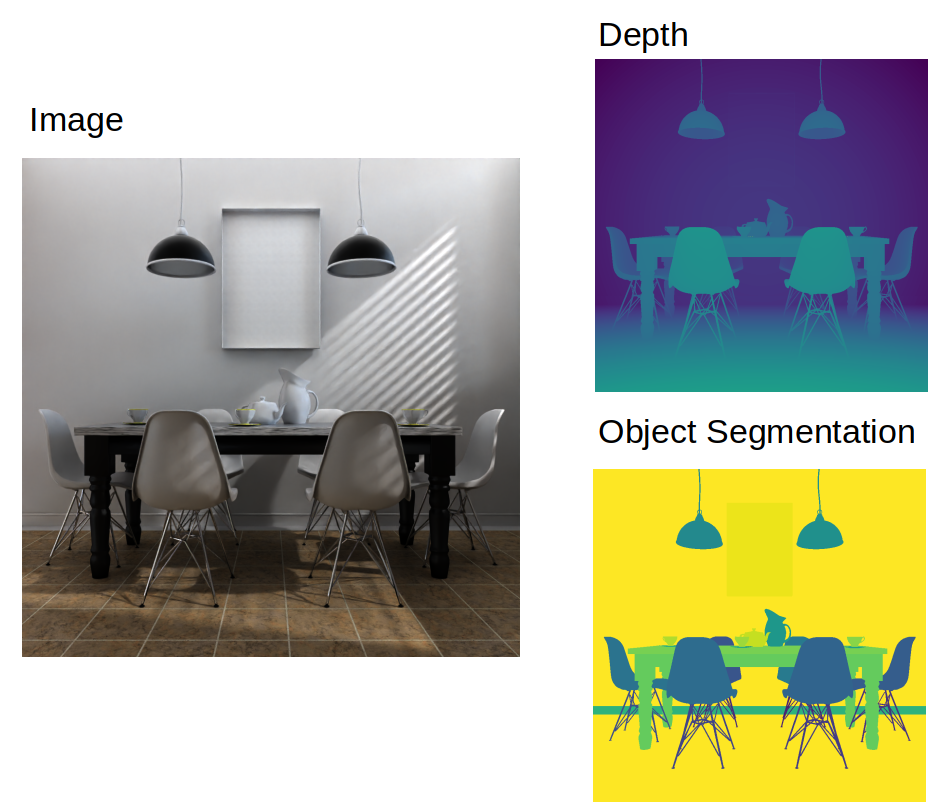
Blender is an amazing software with unlimited cababilities to create 3D environments. Apart from outputing the image itself, in a single pass you can extract many useful information.
Below there is an example showing that you can extract depth and object segmentation. In our opinion it can remove the need to create manual annotation for some type of the problems. For some problem we only consider human annotation as a part of the benchmark.
Even if you cannot use automatically generated data in the final problem – 3D software can create a powerful dataset on which you can pretrain the models to be closer to the final objective.
Simple scene
More complex scene (photorealistic room)
Animation
Conclusion
We believe that synthetic data is essential for further development of AI. Many applications require labeling which is expensive or impossible to do by hand, other applications have a wide underlying data distribution that real datasets do not or cannot fully cover. Moreover, we believe that synthetic data applications will be extended in the future.
If you have a project that could utilize synthetic data contact us and we will see what we can do https://logicai.io/contact.


